1. NLP问题简介
0x1:NLP问题都包括哪些内涵
人们对真实世界的感知被成为感知世界,而人们用语言表达出自己的感知视为文本数据。那么反过来,NLP,或者更精确地表达为文本挖掘,则是从文本数据出发,来尽可能复原人们的感知世界,从而表达真实世界的过程。这里面就包括如图中所示的模型和算法,包括:
(1)文本层:NLP文本表示; (2)文本-感知世界:词汇相关性分析、主题模型、意见情感分析等; (3)文本-真实世界:基于文本的预测等;

显而易见,文本表示在文本挖掘中有着绝对核心的地位,是其他所有模型建构的基础。
0x2:为什么要进行文本表示
特征提取的意义在于把复杂的数据,如文本和图像,转化为数字特征,从而在机器学习中使用。
在机器学习项目中,不管是纯NLP问题还是NLP问题和非文本类混合数据的场景,我们都要面临一个问题,如何将样本集中的文本进行特征表征以及通过向量的方式表达出来。
这就要求我们对样本的原始特征空间进行抽象,将其映射到另一个向量化的定长特征空间中,笔者在这篇blog中对常用的编码和特征工程方式进行一个梳理总结。
0x3:语言模型(Language Model, LM)
统计语言模型是词序列的概率分布,假设有一个 m 长度的文本序列,我们的目的是建立一个能够描述给定词序列对应的概率分布。
掌握不同句子/词组的概率估计方法在NLP中有很多应用,特别是用来生成文本。语言模型在语音识别、机器翻译、词性标注、句法分析、手写识别、信息检索都有广泛的应用。
1. 语言模型的基础模型 - 公式1
![]()
2. 目标函数(基于对数似然)
![]() ,其中C为语料,Context(w) 为词 w 的上下文。
,其中C为语料,Context(w) 为词 w 的上下文。

Relevant Link:
https://blog.csdn.net/tiffanyrabbit/article/details/72650606https://blog.csdn.net/IT_bigstone/article/details/80739807http://www.cnblogs.com/robert-dlut/p/4371973.html
2. 词集模型 - 基于是否出现的one-hot思想的定长向量化表示,向量长度取决于词集维度
词集表示法和下个小节要介绍的词袋模型在基本形式上类似的,都是对公式1 进行了极端地简化,丢失了原始文本序列的序列信息。
0x1:词库表示法
在train_x中,总共有6篇文档,每一行代表一个样本即一篇文档。
我们的目标是将train_x转化为可训练矩阵,即生成每个样本的词向量。可以对train_x分别建立词集模型来解决。
train_x = [["my", "dog", "has", "flea", "problems", "help", "please"], ["maybe", "not", "take", "him", "to", "dog", "park", "stupid"], ["my", "dalmation", "is", "so", "cute", "I", "love", "him"], ["stop", "posting", "stupid", "worthless", "garbage"], ["him", "licks", "ate", "my", "steak", "how", "to", "stop", "him"], ["quit", "buying", "worthless", "dog", "food", "stupid"]]
算法步骤:
1)整合所有的单词到一个集合中,假设最终生成的集合长度为wordSetLen = 31。2)假设文档/样本数为sampleCnt = 6,则建立一个sampleCnt * wordSetLen = 6 * 31的矩阵,这个矩阵被填入有效值之后,就是最终的可训练矩阵m。3)遍历矩阵m,填入0,1有效值。0代表当前列的单词没有出现在当前行的样本/文档中,1代表当前列的单词出现在当前行的样本/文档中。4)最终生成一个6 * 31的可训练矩阵。
读者朋友需要知道的是,实际上,词集模型的表征能力比较弱,在实际的项目中非常少被使用到。
Relevant Link:
https://blog.csdn.net/zk_j1994/article/details/74780030
3. Bag Of Words(BOW)词袋模型 - 基于词频统计的定长向量化表示,向量长度取决于词集维度
词袋模型,顾名思义,把各种词放在一个文本的袋子里,即把文本看做是无序的词的组合。利用统计语言模型来理解词序列的概率分布。
文本中每个词出现的概率仅与自身有关而无关于上下文。这是对公式1 的最极端的简化,丢失了原始文本序列的序列信息。
有一点需要读者注意的是,语言模型与语言特征提取算法是两个不同维度的概念,语言模型是一个框架,在一个具体的框架之下,存在不同的语言特征提取和表征算法。
0x1:Bow模型的特点
1. 特点1:可以很容易得到一个定长的向量,不需要进行padding或者truncate处理;2. 特点2:丢失了原始文本的序列依赖关系,在实际的项目中,读者朋友还是需要仔细思考丢失了序列信息对我们的最终特征表达是否会有影响。 3. 针对特点3,笔者认为,并不说丢失序列关系是BOW模型的缺点,相反,世界上没有绝对的优缺点,只有各具特点的算法,某个特性是有点还是缺点,取决于应用的场景和我们对这个算法的理解深刻程度。
0x2:词库表示法
1. 词库表示法的假设前提
对于一个文档(document),忽略其词序、语法、句法,将其仅仅看做是一个词集合,或者说是词的一个组合,文档中每个词的出现都是独立的,不依赖于其他词是否出,即假设这篇文章的作者在任意一个位置选择一个词汇都不受前面句子的影响而独立选择的。
这是一种非常强的假设,比马尔科夫假设还要强。
词库模型可以看成是独热编码的一种扩展,它为每个单词建立一个特征。
2. 词库表示法有效性的依据
词库模型依据是:存在类似单词集合的文章的语义同样也是类似的
词库模型可以通过有限的编码信息实现有效的文档分类和检索。
3. 举例说明词库表示法
1. 针对单个sentence文本进行编码
假设我们有2段独立的sentence
John likes to watch movies. Mary likes too.John also likes to watch football games.
根据上述两句话中出现的单词, 我们能构建出一个无序字典 (dictionary),字典的key是token化后的单词,字典的value是该词在字典中的索引,字典的length长度是10。
{ "John": 1, "likes": 2, "to": 3, "watch": 4, "movies": 5, "also": 6, "football": 7, "games": 8, "Mary": 9, "too": 10} # John出现了1次;like出现了2次;also没出现
该字典中包含10个单词, 每个单词有唯一索引, 注意它们的顺序和出现在句子中的顺序没有关联。仅仅是是一个索引数字而已。
根据这个字典, 我们能将上述两句话重新表达为下述两个向量:
[1, 2, 1, 1, 1, 0, 0, 0, 1, 1][1, 1, 1, 1, 0, 1, 1, 1, 0, 0]
这两个向量共包含10个元素, 其中第 i 个元素表示字典中第 i 个单词在句子中出现的次数。
因此,BoW模型(词库表示法属于Bow模型的一种)可认为是一种统计直方图 (histogram)。
2. 针对包含多行sentence的document进行编码
每个 document(文本) 可以被看做一个多元 sample(样本)(特征向量)。
还是上面的例子,假设我们有一个包含2段独立的sentence的document
John likes to watch movies. Mary likes too.John also likes to watch football games.
文本的集合可被表示为矩阵形式,每行一条文本,每列对应每个文本中出现的词令牌(如单个词)的频率。
[ [1, 2, 1, 1, 1, 0, 0, 0, 1, 1], [1, 1, 1, 1, 0, 1, 1, 1, 0, 0]]
4. 词库表示法的sklearn封装实现
sklearn对bag-of-word的词频向量化处理进行了封装,scikit-learn为数值特征提取最常见的方式提供了一系列工具
1. tokenizing: 对每个可能的词令牌分成字符串(word split)并赋予整形的id(索引化),比如使用空格和作为令牌分割依据 2. counting: 统计每个词令牌在文档(单个文档,不是整体训练集)中的出现次数 3. normalizing: 在大多数的文档 / 样本中,可以减少重要的次令牌的权重
CountVectorizer 在单个类中实现了令牌化和出现频数统计:
令牌化字符串,提取至少两个字母的词
from sklearn.feature_extraction.text import CountVectorizerif __name__ == '__main__': vectorizer = CountVectorizer(min_df=1) analyze = vectorizer.build_analyzer() print analyze("This is a text document to analyze.")"" [u'this', u'is', u'text', u'document', u'to', u'analyze'] 每个在拟合中被分析器发现的词被指派了一个独一无二的索引,在结果矩阵中表示一列。对于列的翻译可以被如下方式检索
from sklearn.feature_extraction.text import CountVectorizerif __name__ == '__main__': corpus = [ 'This is the first document.', 'This is the second second document.', 'And the third one.', 'Is this the first document?', ] vectorizer = CountVectorizer(min_df=1) X = vectorizer.fit_transform(corpus) print vectorizer.get_feature_names() print X.toarray()''''[u'and', u'document', u'first', u'is', u'one', u'second', u'the', u'third', u'this']总体样本库中共有9个token word[[0 1 1 1 0 0 1 0 1] [0 1 0 1 0 2 1 0 1] [1 0 0 0 1 0 1 1 0] [0 1 1 1 0 0 1 0 1]]每一行代表一个sentence,共4行(4个sentence)每一列代表一个token词的词频,共9列(9个token word)''''
对运行的结果我们仔细观察下,第一个sentence和最后一个文本sentence分别表达了陈述和疑问两种句式(token word出现的位置不一样,造成表达意思的不同),但是因为它们包含的词都相同。
但是进过词袋编码后,得到的特征向量都是一样的,很显然,这个编码过程丢失了这个疑问句的句式信息,这就是词袋模型最大的缺点:不能捕获词间相对位置信息
'This is the first document.','Is this the first document?',[[0 1 1 1 0 0 1 0 1] [0 1 1 1 0 0 1 0 1]]
Relevant Link:
http://www.cnblogs.com/platero/archive/2012/12/03/2800251.htmlhttp://feisky.xyz/machine-learning/resources/github/spark-ml-source-analysis/%E7%89%B9%E5%BE%81%E6%8A%BD%E5%8F%96%E5%92%8C%E8%BD%AC%E6%8D%A2/CountVectorizer.html
0x3:TF-IDF(Term Frequency-Inverse Document Frequency)表示法
TF-IDF(term frequency–inverse document frequency)是一种用于信息检索与数据挖掘的常用加权技术。
TF-IDF产生的特征向量是带有倾向性的,主要可以被用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。
字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
TF-IDF属于BOW语言模型的一种,但是在基础的词频统计之上增加和单个词和全局词集的相对关系。同时,TF-IDF也不关注词序信息,TF-IDF同样也丢失了词序列信息。
1. TF-IDF的加权词频统计思想
用通俗的话总结TF-IDF的主要思想是:
如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类,也即可以作为所谓的关键字。
假定现在有一篇长文《中国的蜜蜂养殖》,我们准备用计算机提取它的关键词,一个容易想到的思路,就是找到出现次数最多的词。如果某个词很重要,它应该在这篇文章中多次出现。
于是,我们进行"词频"(Term Frequency,缩写为TF)统计。
在统计结束后我们会发现,出现次数最多的词是 "的"、"是"、"在" 这一类最常用的词。它们叫做"停用词"(stop words),在大多数情况下这对找到结果毫无帮助、我们采取过滤掉停用词的策略。
假设我们把它们都过滤掉了,只考虑剩下的有实际意义的词。这样又会遇到了另一个问题,我们可能发现"中国"、"蜜蜂"、"养殖"这三个词的出现次数一样多。这是不是意味着,作为关键词,它们的重要性是一样的?
显然不是这样。因为"中国"是很常见的词(在日常的语料库中出现频率较高),相对而言,"蜜蜂"和"养殖"不那么常见(倾向于专有领域的词)。
如果这三个词在一篇文章的出现次数一样多,有理由认为,"蜜蜂"和"养殖"的重要程度要大于"中国",也就是说,在关键词排序上面,"蜜蜂"和"养殖"应该排在"中国"的前面。所以,我们需要一个重要性调整系数,衡量一个词是不是常见词。如果某个词比较少见,但是它在这篇文章中多次出现,那么它很可能就反映了这篇文章的特性,正是我们所需要的关键词
用统计学语言表达,就是在词频的基础上,要对每个词分配一个"重要性"权重
1. 最常见的词("的"、"是"、"在")给予最小的权重;2. 较常见的词("中国")给予较小的权重;3. 较少见的词("蜜蜂"、"养殖")给予较大的权重; 这个权重叫做"逆文档频率"(Inverse Document Frequency,缩写为IDF),它的大小与一个词的常见程度成反比,它的作用是对原始词频权重进行反向调整。
知道了"词频"(TF)和"逆文档频率"(IDF)以后,将这两个值相乘,就得到了一个词的TF-IDF值。某个词对文章的重要性越高,它的TF-IDF值就越大。所以,排在最前面的几个词,就是这篇文章的关键词
2. TF-IDF算法流程
第一步 - 计算词频

考虑到文章有长短之分,为了便于不同文章的比较,进行"词频"归一化"

第二步 - 计算逆文档频率
这时,需要一个语料库(corpus),用来模拟语言的总体使用环境

如果一个词越常见,那么分母就越大,逆文档频率就越小越接近0。分母之所以要加1,是为了避免分母为0(即所有文档都不包含该词),log表示对得到的值取对数。
第三步 - 计算TF-IDF
![]()
可以看到,TF-IDF与一个词在文档中的出现次数成正比,与该词在整个语言中的出现次数成反比
以《中国的蜜蜂养殖》为例:
假定该文长度为1000个词,"中国"、"蜜蜂"、"养殖"各出现20次,则这三个词的"词频"(TF)都为0.02。然后,搜索Google发现,包含"的"字的网页共有250亿张,假定这就是中文网页总数包含"中国"的网页共有62.3亿张;包含"蜜蜂"的网页为0.484亿张;包含"养殖"的网页为0.973亿张。
则它们的逆文档频率(IDF)和TF-IDF如下
中国IDF = math.log(250 / 63.3) = 1.37357558871TF-IDF = IDF * 0.02 = 0.0274715117742蜜蜂IDF = math.log(250 / 63.3) = 5.12671977312 TF-IDF = IDF * 0.02 = 0.102534395462养殖IDF = math.log(250 / 63.3) = 4.84190569082 TF-IDF = IDF * 0.02 = 0.0968381138164
从上表可见,"蜜蜂"的TF-IDF值最高,"养殖"其次,"中国"最低。所以,如果只选择一个词,"蜜蜂"就是这篇文章的关键词
3. TF-IDF的sklearn封装实现
因为 tf–idf 在特征提取中经常被使用,所以有一个类: TfidfVectorizer 在单个类中结合了所有类和类中的选择:
from sklearn.feature_extraction.text import TfidfVectorizerif __name__ == '__main__': corpus = [ 'This is the first document.', 'This is the second second document.', 'And the third one.', 'Is this the first document?', ] vectorizer = TfidfVectorizer(min_df=1) tfidf = vectorizer.fit_transform(corpus) print vectorizer.vocabulary_ print tfidf.toarray() '''' {u'and': 0, u'third': 7, u'this': 8, u'is': 3, u'one': 4, u'second': 5, u'the': 6, u'document': 1, u'first': 2} [[ 0. 0.43877674 0.54197657 0.43877674 0. 0. 0.35872874 0. 0.43877674] [ 0. 0.27230147 0. 0.27230147 0. 0.85322574 0.22262429 0. 0.27230147] [ 0.55280532 0. 0. 0. 0.55280532 0. 0.28847675 0.55280532 0. ] [ 0. 0.43877674 0.54197657 0.43877674 0. 0. 0.35872874 0. 0.43877674]] 可以看到,document在整个语料库中都出现,所以权重被动态降低了
Relevant Link:
http://www.ruanyifeng.com/blog/2013/03/tf-idf.htmlhttp://www.cnblogs.com/ybjourney/p/4793370.htmlhttp://www.cc.ntu.edu.tw/chinese/epaper/0031/20141220_3103.html https://nlp.stanford.edu/IR-book/html/htmledition/tf-idf-weighting-1.html http://sklearn.lzjqsdd.com/modules/feature_extraction.htm
0x4:LSA(Latent Semantic Analysis)潜在语义分析表示法
笔者思考:LSA并不单纯地像词库表示法和TF-IDF一样,仅仅进行文档的向量化表征。相比之下,LSA算法在传统词频统计语言模型之上进行了语义分析。所以,严格来说,LSA可能并不能算是一个单纯的文本特征表征法,LSA产出的是包含语义特性的向量特征表征。
1. LSA是什么
潜在语义分析LSA(Latent Semantic Analysis )也叫作潜在语义索引LSI( Latent Semantic Indexing ) 顾名思义是通过分析文章(documents )来挖掘文章的潜在意思或语义(concepts )。
不同的单词可以表示同一个语义,或一个单词同时具有多个不同的意思,这些的模糊歧义是LSA主要解决的问题。

例如,bank 这个单词如果和mortgage, loans, rates 这些单词同时出现时,bank 很可能表示金融机构的意思。可是如果bank 这个单词和lures, casting, fish一起出现,那么很可能表示河岸的意思。
2. LSA的基本假设
一篇文章(包含很多sentence的document)可以随意地选择各种单词来表达,因此不同的作者的词语选择风格都大不相同,表达的语义也因此变得模糊。
这种单词选择的随机性必然将噪声的引入到“单词-语义关系”(word-concept relationship)。
LSA能过滤掉一些噪声,同时能在语料库中找出一个最小的语义子集( to find the smallest set of concepts that spans all the documents)。所以本质上LSA也可以理解为一种信息压缩的算法。
LSA引入了一些重要的假设
1. 文章通过”bags of words”词频语言模型的形式来表示,也就是说单词的出现顺数并不重要,而与单词在文中出现的次数相关2. 语义通过“一组”最有可能同时出现的单词来表示。例如”leash”, “treat”, “obey” 常出现在关于 dog training的文章里面,一组单词共同决定了一种语义。3. 每个单词假设只有一个意思,当然这个假设在遇到““banks””(既表示河岸也表示金融银行)这种情况当然不合适,但是这个假设将有助于简化问题难度。
3. LSA的工作原理
1)词-文档矩阵(Occurences Matrix) - 将原始document转换为词频统计稀疏矩阵
LSA 使用词-文档矩阵来描述一个词语是否在一篇文档中。
词-文档矩阵式一个稀疏矩阵,其行代表词语,其列代表文档。
一般情况下,词-文档矩阵的元素是该词在文档中的出现次数(词库表示法),也可以是是该词语的TF-IDF。词-文档矩阵的本质就是传统的词频语言模型,后面的LSA语义分析在基于传统的词频语言模型进行了拓展。
2)SVD奇异值矩阵分解 - 降维
在构建好词-文档矩阵之后,LSA将对该矩阵进行降维,来找到词-文档矩阵的一个低阶近似。降维的原因有以下几点:
1. 原始的词-文档矩阵太大导致计算机无法处理,从此角度来看,降维后的新矩阵式原有矩阵的一个近似;2. 原始的词-文档矩阵中有噪音,从此角度来看,降维后的新矩阵式原矩阵的一个去噪矩阵,即冗余信息压缩;3. 原始的词-文档矩阵过于稀疏。原始的词-文档矩阵精确的反映了每个词是否“出现”或“出现的频次”于某篇文档的情况,然而我们往往对某篇文档“相关”的所有词更感兴趣,因此我们需要发掘一个词的各种同义词的情况;4. 将维可以解决一部分同义词的问题,也能解决一部分二义性问题。具体来说,原始词-文档矩阵经过降维处理后,原有词向量对应的二义部分会加到和其语义相似的词上,而剩余部分则减少对应的二义分量;
降维的结果是不同的词或因为其语义的相关性导致合并,如下面将car和truck进行了合并:
{(car), (truck), (flower)} --> {(1.3452 * car + 0.2828 * truck), (flower)}
3)SVD降维推导
假设 X 矩阵是词-文档矩阵,其元素(i,j)代表词语 i 在文档 j 中的出现次数,则 X矩阵看上去是如下的样子:
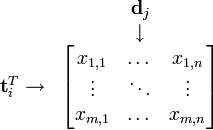
可以看到,每一行代表一个词的向量,该向量描述了该词和所有文档的关系。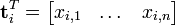
相似的,一列代表一个文档向量,该向量描述了该文档与所有词的关系。
词向量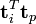 的点乘可以表示这两个单词在文档集合中的相似性。矩阵
的点乘可以表示这两个单词在文档集合中的相似性。矩阵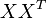 包含所有词向量点乘的结果,元素(i,p)和元素(p,i)具有相同的值,代表词 p 和词 i 的相似度。
包含所有词向量点乘的结果,元素(i,p)和元素(p,i)具有相同的值,代表词 p 和词 i 的相似度。
类似的,矩阵 包含所有文档向量点乘的结果,也就包含了所有文档总体的相似度。
包含所有文档向量点乘的结果,也就包含了所有文档总体的相似度。
现在假设存在矩阵 的一个分解,即矩阵可分解成正交矩阵U和V,和对角矩阵
的一个分解,即矩阵可分解成正交矩阵U和V,和对角矩阵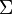 的乘积。
的乘积。
这种分解叫做奇异值分解(SVD),即:

因此,词与文本的相关性矩阵可以表示为:
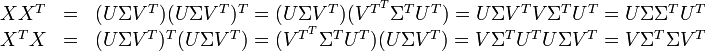
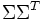 与
与 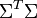 是对角矩阵,因此
是对角矩阵,因此  肯定是由 的特征向量组成的矩阵,同理
肯定是由 的特征向量组成的矩阵,同理 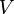 是 特征向量组成的矩阵。这些特征向量对应的特征值即为 中的元素。综上所述,这个分解看起来是如下的样子:
是 特征向量组成的矩阵。这些特征向量对应的特征值即为 中的元素。综上所述,这个分解看起来是如下的样子: 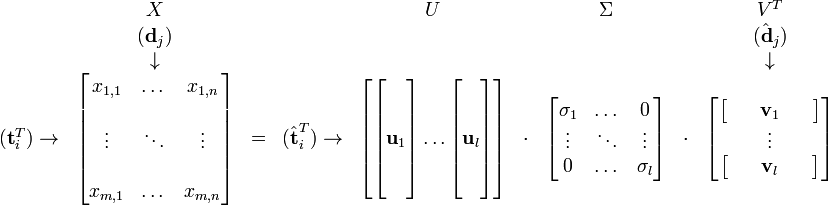
 被称作是 奇异值,而
被称作是 奇异值,而  和
和  则叫做 左奇异向量和 右奇异向量。
则叫做 左奇异向量和 右奇异向量。 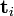 只与U矩阵的第 i 行有关,我们则称第 i 行为
只与U矩阵的第 i 行有关,我们则称第 i 行为  。
。 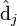 只与
只与 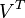 中的第 j 列有关,我们称这一列为 。 与 并非特征值,但是其由矩阵所有的特征值所决定。
中的第 j 列有关,我们称这一列为 。 与 并非特征值,但是其由矩阵所有的特征值所决定。 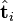 与含有 k 个奇异值的矩阵相乘,实质是从高维空间到低维空间的一个变换,可以理解为是一个高维空间到低维空间的近似。
与含有 k 个奇异值的矩阵相乘,实质是从高维空间到低维空间的一个变换,可以理解为是一个高维空间到低维空间的近似。 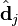 也存在这样一个从高维空间到低维空间的变化。
也存在这样一个从高维空间到低维空间的变化。 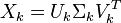
4. LSA的应用
- 在低维语义空间可对文档进行比较,进而可用于文档聚类和文档分类。
- 在翻译好的文档上进行训练,可以发现不同语言的相似文档,可用于跨语言检索。
- 发现词与词之间的关系,可用于同义词、歧义词检测。.
- 通过查询映射到语义空间,可进行信息检索。
- 从语义的角度发现词语的相关性,可用于“选择题回答模型”(multi choice qustions answering model)。
5. LSA算法局限性
- 新生成的矩阵的解释性比较差。造成这种难以解释的结果是因为SVD只是一种数学变换,并无法对应成现实中的概念。
- LSA无法扑捉一词多意的现象。在原始词-向量矩阵中,每个文档的每个词只能有一个含义。比如同一篇文章中的“The Chair of Board"和"the chair maker"的chair会被认为一样。在语义空间中,含有一词多意现象的词其向量会呈现多个语义的平均。相应的,如果有其中一个含义出现的特别频繁,则语义向量会向其倾斜。
- LSA具有词袋模型的缺点,即在一篇文章,或者一个句子中忽略词语的先后顺序。
- LSA的概率模型假设文档和词的分布是服从联合正态分布的,但从观测数据来看是服从泊松分布的。因此LSA算法的一个改进PLSA使用了多项分布,其效果要好于LSA。
0x5:在实际项目中需要注意的点
1. 词袋模型编码后的词向量 padding or truncating
词袋模型编码得到的词向量长度,等于词袋中词集的个数。
然而,通常在一个海量的document集合中,词集的个数是非常巨大的。如果全部都作为词集,那么最终编码得到的词向量会非常巨大,同时也很容易遇到稀疏问题。
因此,我们一般需要在特征编码前进行padding or truncating,具体的做法可以由以下两种:
1. 根据TOP Order排序获取指定数量的词集,例如取 top 8000高频词作为词集;2. 针对编码后得到的词向量进行 padding or truncating
这两种做法的最终效果是一样的。
Relevant Link:
https://blog.csdn.net/roger__wong/article/details/41175967https://blog.csdn.net/zhzhji440/article/details/47193731
4. N-Gram语言模型 - 一种多词组合语言模型
0x1:N-Gram算法思想
1. 完整序列语言模型存在的问题
我们回想公式1,语言模型序列假设:第n个词的出现只与前面N-1个词相关,而与其它任何词都不相关,整句的概率就是各个词出现概率的乘积。
![]()
这种模型虽然非常合理(对真实情况的模拟逼近),但是存在两个比较严重的缺陷
1. 一个缺陷是参数空间过大,不可能实用化,一个序列长度为N的参数个数为: N!2. 另外一个缺陷是数据稀疏严重,越长的序列的越不容易出现,整个参数矩阵上会有很多0值
2. Ngram(N元模型)- 马尔科夫有限词序列依赖假设
为了解决上一小节提到的2个缺陷,我们引入另一个近似模型:马尔科夫假设,一个词的出现仅仅依赖于它前面出现的有限的一个或者几个词,这种模型就大大减少了需要参与计算的先验参数。
例如,如果一个词的出现仅依赖于它前面出现的一个词,那么我们就称之为 bigram(2-gram)
P(T) = P(W1W2W3…Wn)=P(W1)P(W2|W1)P(W3|W1W2)…P(Wn|W1W2…Wn-1)
≈P(W1)P(W2|W1)P(W3|W2)…P(Wn|Wn-1)0x2:N-gram语言模型下的词序特征表征方法
Ngram和BOW模型的区别就在于,对原始语言模型公式1 的假设简化程度不同,Ngram保留了有限长度的序列信息。除此之外,Ngram也同样可以应用词库表示法、以及TF-IDF等表示法。
0x3:基于n-gram的机器学习应用
我们已经了解了n-gram的词频生成方法以及sentence概率估计原理,接下来看看n-gram可以用在哪些实际的场景中
1. 基于Ngram模型定义的字符串距离
模糊匹配的关键在于如何衡量两个长得很像的单词(或字符串)之间的“差异”,这种差异通常又称为“距离”。除了可以定义两个字符串之间的编辑距离(通常利用Needleman-Wunsch算法或Smith-Waterman算法),还可以定义它们之间的Ngram距离。
假设有一个字符串S,那么该字符串的Ngram就表示按长度N切分原sentence得到的词段(长度为N),也就是S中所有长度为N的子字符串。设想如果有两个字符串,然后分别求它们的Ngram,那么就可以从它们的共有子串的数量这个角度去定义两个字符串间的Ngram距离。但是仅仅是简单地对共有子串进行计数显然也存在不足,这种方案显然忽略了两个字符串长度差异可能导致的问题。比如字符串girl和girlfriend,二者所拥有的公共子串数量显然与girl和其自身所拥有的公共子串数量相等,但是我们并不能据此认为girl和girlfriend是两个等同的匹配。为了解决该问题,有研究员提出以非重复的Ngram分词为基础来定义Ngram距离,公式表示如下:
|GN(S1)|+|GN(S2)|−2×|GN(S1)∩GN(S2)|
此处,|GN(S1)||GN(S1)|是字符串S1S1的Ngram集合,N值一般取2或者3。以N=2为例对字符串Gorbachev和Gorbechyov进行分段,可得如下结果
Go or rb ba ac ch he evGo or rb be ec ch hy yo ov
结合上面的公式,即可算得两个字符串之间的距离是8 + 9 − 2 × 4 = 9。显然,字符串之间的距离越小,它们就越接近。当两个字符串完全相等的时候,它们之间的距离就是0。可以看到,这种公式充分考虑到了字符串的长度区别和相同词组2者的共同作用
2. 利用Ngram模型评估语句是否合理
从统计的角度来看,自然语言中的一个句子S可以由任何词串构成,不过概率P(S)有大有小。例如:
S1 = 我刚吃过晚饭S2 = 刚我过晚饭吃
显然,对于中文而言S1是一个通顺而有意义的句子,而S2则不是,所以对于中文来说P(S1)>P(S2)
假设我们现在有一个语料库如下,其中<s1><s2>是句首标记,</s2></s1>是句尾标记:
yes no no no no yes no no no yes yes yes no
下面我们的任务是来评估如下这个句子的概率:
yes no no yes
我们利用trigram来对这句话进行词组分解

所以我们要求的概率就等于:1/2×1×1/2×2/5×1/2×1=0.05
3. 基于Ngram模型的文本分类器
Ngram如何用作文本分类器的呢?只要根据每个类别的语料库训练各自的语言模型,实质上就是每一个类别都有一个概率分布,当新来一个文本的时候,只要根据各自的语言模型,计算出每个语言模型下这篇文本的发生概率,文本在哪个模型的概率大,这篇文本就属于哪个类别了!
4. spam filtering
基于n-gram进行垃圾邮件判断我理解本质上就是在进行文本分类,通过训练"good email"和"spam email"的n-gram词频表,对新来的email分别根据2个词频表计算最大似然概率,根据得出概率最大的那个词频表判断该email属于哪一类
0x4:sklearn封装实现
from sklearn.feature_extraction.text import CountVectorizerif __name__ == '__main__': corpus = [ 'This is the first document.', 'This is the second second document.', 'And the third one.', 'Is this the first document?', ] bigram_vectorizer = CountVectorizer(ngram_range=(1, 2), token_pattern=r'\b\w+\b', min_df = 1) X_2 = bigram_vectorizer.fit_transform(corpus).toarray() print X_2 print bigram_vectorizer.vocabulary_'''' [[0 0 1 1 1 1 1 0 0 0 0 0 1 1 0 0 0 0 1 1 0] [0 0 1 0 0 1 1 0 0 2 1 1 1 0 1 0 0 0 1 1 0] [1 1 0 0 0 0 0 0 1 0 0 0 1 0 0 1 1 1 0 0 0] [0 0 1 1 1 1 0 1 0 0 0 0 1 1 0 0 0 0 1 0 1]]{u'and': 0, u'the second': 14, u'is': 5, u'this the': 20, u'one': 8, u'and the': 1, u'second': 9, u'first document': 4, u'is the': 6, u'second document': 10, u'the third': 15, u'document': 2, u'the first': 13, u'is this': 7, u'third': 16, u'this': 18, u'second second': 11, u'third one': 17, u'the': 12, u'this is': 19, u'first': 3} 上面输入的结果,我们看第一行的前3个:0 0 1;0号index代表and,1号index代表and the,2号index代表document,0和1号索引都在第一个sentence里未出现,所以g-gram之后的one-hot vector填0,而document出现在第一个sentence的最后一个位置,故填1,可见n-gram并不关注词在样本中的具体位置。n-gram保留的词序列只是它自己的context上下文的词组序列
因为n-gram进行了N*N无序组合(用one-hot的思想抽象成了一个定长的vector),因此矢量化提取的词因此变得很大,同时可以在定位模式时消歧义,同时我们注意到,n-gram本质上还是一种bag-of-words模型,因此n-gram编码后的vector丢失了原始sentence的序列,它只保存了N子序列的词组关系
Relevant Link:
http://blog.csdn.net/lengyuhong/article/details/6022053https://flystarhe.github.io/2016/08/16/ngram/http://blog.csdn.net/baimafujinji/article/details/51281816https://en.wikipedia.org/wiki/Bag-of-words_modelhttp://www.52nlp.cn/tag/n-gramhttps://blog.csdn.net/tiffanyrabbit/article/details/72650606
5. RNN/LSTM - 长序列语言模型
RNN/LSTM是非词频统计型的语言模型。
6. Emberding词向量空间表示法
7. AutoEncodder - 基于深度神经网络隐藏层的信息压缩的特征提取能力得到词序列特征表示
(未完待续)
Copyright (c) 2017 LittleHann All rights reserved